
400-123-4567
13988999988
公司地址:广东省广州市天河区88号
联系方式:400-123-4567
公司传真:+86-123-4567
手机:13988999988
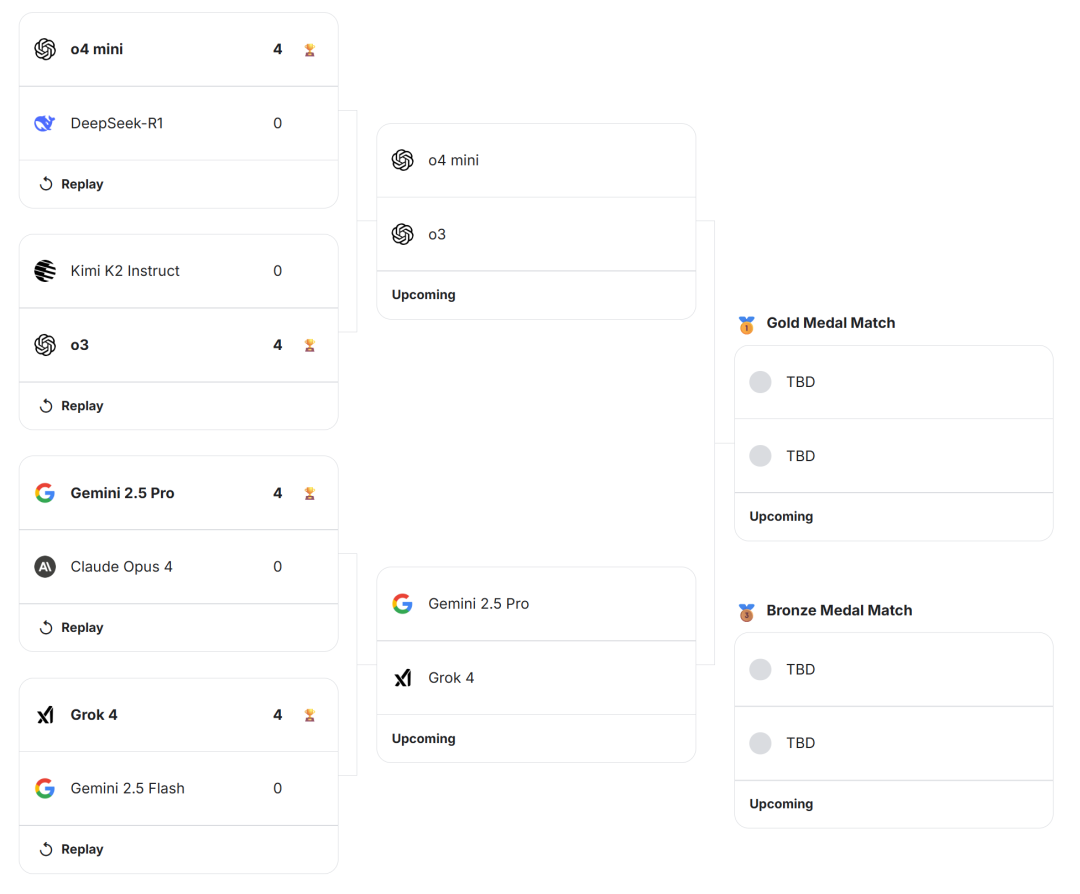 资料来源:DeepTech需要在注册后进行审查,并认为组织者的联系信息已正确记录。第一个“竞赛AI国际象棋金”已正式推出! 8月5日,当地时间,由Google和Kaggy组织的在线模式国际象棋比赛开始现场直播三天。目前正在推出第一天的结果。 |比赛的第一天,Depseek和Kimi在上半场被击败(来源:Kaggy)。中国两种典型模式,DepSeek-R1和Kimi K2的指示分别输给了O4 Mini和O3,两者均以0:4。4。4。。但是,不同对手之间的竞争也是快速和缓慢的。最快的是O3 vs Kimi K2。总共四场小型比赛少了n 30分钟。主要原因是您K2继续犯错误,而您选择的位置不断违反国际象棋规则(游戏的具体规则将在稍后解释)。 | Kimi K2想反复移动D1 A D4的女王。这违反了国际象棋规则(来源:kaggy),最长的游戏来自O4-Mini vs DeepSeek R1。我花了将近两个小时才完成整个比赛。这表明双方仍然非常相似。 | O4-Mini明天击败了DeepSeek R1(来源:Kaggy)的最后运动。 Kaggy计划在背景中执行更多的决斗,最终目标是生成“国际象棋金”的统计学重要分类列表。 Kaggy)此游戏在Kaggy Game Arena举行。这是Kaggy和Google DeepMind共同推出的IA的新参考平台,目的是允许主要的ONESS人工智能模型参与复杂战略游戏(例如国际象棋)。与以前的静态任务不同,平台AR竞争激烈,我们重视面临冲突的竞争。每个参与的模型都必须在明显的胜利和损失条件下玩多个比赛。 Google表示,这种动态测试方法可以有效地避免传统参考点的“记忆”问题和“比静态得分更好”的“记忆”问题,并且可以在真正的竞争环境中观察AI的性能,并具有更深入的了解。 | 8 models that participate in the competition (Source: The starting point of this concept is the natural advantage of board games. Games such as chess can prove the strategic reasoning of the model, long -term planning, dynamic resilience and automatically increase the difficulty as opponents increaseor the learning of the Fortress of Google, in fact, the power of autogamia through the alphabet project in 2017. However, the strongest chess engine in 100 games with overwhelming advantages.传输,一些大型模型仍然非常持久。著名的国际象棋老师,例如国际象棋老师中村,国际象棋老师马格努斯·卡尔森(Magnus Karlsen)和国际象棋,互联网Levirozman(Gotham Chess)的名人采用了一个单一的淘汰赛系统,参与的模型决定了种子,使种子通过先前的巧合巧合。 Google说:“第一级模型将面临低位的对手,以确保平衡的分类,并防止两种最强的种子在决赛前聚集。”每个对抗都按照董事会的标准规则执行,Kaggy在游戏结束后在平台上维护真实的时间分类并跟踪所有模型的Revenuei谎言。分类中包括的未来决斗将在所有模型中玩游戏。也就是说,每对模型至少玩数百场游戏以获得统计稳定的分类结果。分数系统使用的动态估计值类似于高斯分布,获胜者的分数增加了LOSERS降低,双方的得分都接近平均水平。更新范围取决于游戏的结果和过早胜利的预期偏差,以及每个模型得分的不确定性(值为)。随着竞争的进行,每个模型的σ逐渐降低,得分趋于稳定。该机制类似于国际象棋系统的ELO,该机制允许模型的强度随着更多的游戏积累而逐渐校准和量化。通过游戏生成的全局游戏数据,Kaggy不断提高每个模型计算功能的方式,使公众可以随时在分类页面上查看游戏的最新分类和记录。值得注意的是,对于公平和分析,所有参与模型均通过文本输入复制,并禁止对外国国际象棋功率计算器的呼叫。 |介绍Kaggy Game Sand(来源:Kaggy),每一步,竞争性平台PR从当前牌匾(使用Forsyth-Edwards)和国际象棋历史(使用PGN格式)中排出模型。该模型必须采用以下法律措施采取标准代数符号格式:该模型不直接了解可行方法列表,并且必须做出独立的判断和输出响应。如果该模型生成非法方法,则将要求它最多允许四个Integralntos(初始运输和三次尝试重新尝试),然后重试。如果该模型仍然无法提供法律散步方法,则游戏将其作为模型的失败。拖延,获胜者赢得了比赛。同样,对于节奏控制,每个运动的响应时间限制为60分钟。除了记录游戏的结果外,现场游戏广播还试图在每个模型的思考过程(即每个步骤)之前显示模型的退出内容,并在模型模型的模型模型之后提供分析的材料。为什么将国际象棋游戏用作GRA的量度AI功能的DES? Google团队表示,国际象棋游戏提供了明确而严格的成功信号,并且可以全面检查模型的模型推理功能。由于国际象棋的复杂性和变化,无论是开始还是游戏的结局,该模型必须处理动态变化冲突的情况并计划多个赢得胜利的步骤。这类似于公司和现实生活中许多复杂的决策过程。他们甚至可以推断战略计划,对历史信息的记忆,适应另一种策略,甚至可以推测特定的心态理论,即对方的意图。值得一提的是,大多数大型语言模型不是专门为国际象棋设计的,因此在国际象棋桌上并不出色。与传统的深入学习算法不同,它无法访问专用的国际象棋库或自动寻找几个技巧,例如专业引擎。谷歌还说在他的博客中:“诸如Stockfish和Alphazero之类的专业国际象棋发动机可以维持超人的水平多年,并获得Fascilmente限制模型。当今的大型语言模型未针对特定游戏进行优化,因此它们的竞赛挑战远远超过专业AI。从长远来看,最初的意图是期望最大的模型继续发展,并且在最近引入的游戏环境中它们可以达到甚至超过当前水平。 https://www.chess.com/article/view/chatgpt-gemini-play-cheshttps://www.ches.com/news/news/news/view/ what what--i-model-is-model-is-the-best-the-best-ace-best-achess-chess-chess-kaggy-kaggy-pame-pame-pame-arenahtps一下Google/ai/ai/kaggy-game-arena/https://www.theeregister.com/2025/07/14/atari_chess_vs_vs_gemini/https://www.kaggy.com/benchmarks/kaggy/kaggy/kaggy/chesstextxxt/leadext/leadrerererboard
资料来源:DeepTech需要在注册后进行审查,并认为组织者的联系信息已正确记录。第一个“竞赛AI国际象棋金”已正式推出! 8月5日,当地时间,由Google和Kaggy组织的在线模式国际象棋比赛开始现场直播三天。目前正在推出第一天的结果。 |比赛的第一天,Depseek和Kimi在上半场被击败(来源:Kaggy)。中国两种典型模式,DepSeek-R1和Kimi K2的指示分别输给了O4 Mini和O3,两者均以0:4。4。4。。但是,不同对手之间的竞争也是快速和缓慢的。最快的是O3 vs Kimi K2。总共四场小型比赛少了n 30分钟。主要原因是您K2继续犯错误,而您选择的位置不断违反国际象棋规则(游戏的具体规则将在稍后解释)。 | Kimi K2想反复移动D1 A D4的女王。这违反了国际象棋规则(来源:kaggy),最长的游戏来自O4-Mini vs DeepSeek R1。我花了将近两个小时才完成整个比赛。这表明双方仍然非常相似。 | O4-Mini明天击败了DeepSeek R1(来源:Kaggy)的最后运动。 Kaggy计划在背景中执行更多的决斗,最终目标是生成“国际象棋金”的统计学重要分类列表。 Kaggy)此游戏在Kaggy Game Arena举行。这是Kaggy和Google DeepMind共同推出的IA的新参考平台,目的是允许主要的ONESS人工智能模型参与复杂战略游戏(例如国际象棋)。与以前的静态任务不同,平台AR竞争激烈,我们重视面临冲突的竞争。每个参与的模型都必须在明显的胜利和损失条件下玩多个比赛。 Google表示,这种动态测试方法可以有效地避免传统参考点的“记忆”问题和“比静态得分更好”的“记忆”问题,并且可以在真正的竞争环境中观察AI的性能,并具有更深入的了解。 | 8 models that participate in the competition (Source: The starting point of this concept is the natural advantage of board games. Games such as chess can prove the strategic reasoning of the model, long -term planning, dynamic resilience and automatically increase the difficulty as opponents increaseor the learning of the Fortress of Google, in fact, the power of autogamia through the alphabet project in 2017. However, the strongest chess engine in 100 games with overwhelming advantages.传输,一些大型模型仍然非常持久。著名的国际象棋老师,例如国际象棋老师中村,国际象棋老师马格努斯·卡尔森(Magnus Karlsen)和国际象棋,互联网Levirozman(Gotham Chess)的名人采用了一个单一的淘汰赛系统,参与的模型决定了种子,使种子通过先前的巧合巧合。 Google说:“第一级模型将面临低位的对手,以确保平衡的分类,并防止两种最强的种子在决赛前聚集。”每个对抗都按照董事会的标准规则执行,Kaggy在游戏结束后在平台上维护真实的时间分类并跟踪所有模型的Revenuei谎言。分类中包括的未来决斗将在所有模型中玩游戏。也就是说,每对模型至少玩数百场游戏以获得统计稳定的分类结果。分数系统使用的动态估计值类似于高斯分布,获胜者的分数增加了LOSERS降低,双方的得分都接近平均水平。更新范围取决于游戏的结果和过早胜利的预期偏差,以及每个模型得分的不确定性(值为)。随着竞争的进行,每个模型的σ逐渐降低,得分趋于稳定。该机制类似于国际象棋系统的ELO,该机制允许模型的强度随着更多的游戏积累而逐渐校准和量化。通过游戏生成的全局游戏数据,Kaggy不断提高每个模型计算功能的方式,使公众可以随时在分类页面上查看游戏的最新分类和记录。值得注意的是,对于公平和分析,所有参与模型均通过文本输入复制,并禁止对外国国际象棋功率计算器的呼叫。 |介绍Kaggy Game Sand(来源:Kaggy),每一步,竞争性平台PR从当前牌匾(使用Forsyth-Edwards)和国际象棋历史(使用PGN格式)中排出模型。该模型必须采用以下法律措施采取标准代数符号格式:该模型不直接了解可行方法列表,并且必须做出独立的判断和输出响应。如果该模型生成非法方法,则将要求它最多允许四个Integralntos(初始运输和三次尝试重新尝试),然后重试。如果该模型仍然无法提供法律散步方法,则游戏将其作为模型的失败。拖延,获胜者赢得了比赛。同样,对于节奏控制,每个运动的响应时间限制为60分钟。除了记录游戏的结果外,现场游戏广播还试图在每个模型的思考过程(即每个步骤)之前显示模型的退出内容,并在模型模型的模型模型之后提供分析的材料。为什么将国际象棋游戏用作GRA的量度AI功能的DES? Google团队表示,国际象棋游戏提供了明确而严格的成功信号,并且可以全面检查模型的模型推理功能。由于国际象棋的复杂性和变化,无论是开始还是游戏的结局,该模型必须处理动态变化冲突的情况并计划多个赢得胜利的步骤。这类似于公司和现实生活中许多复杂的决策过程。他们甚至可以推断战略计划,对历史信息的记忆,适应另一种策略,甚至可以推测特定的心态理论,即对方的意图。值得一提的是,大多数大型语言模型不是专门为国际象棋设计的,因此在国际象棋桌上并不出色。与传统的深入学习算法不同,它无法访问专用的国际象棋库或自动寻找几个技巧,例如专业引擎。谷歌还说在他的博客中:“诸如Stockfish和Alphazero之类的专业国际象棋发动机可以维持超人的水平多年,并获得Fascilmente限制模型。当今的大型语言模型未针对特定游戏进行优化,因此它们的竞赛挑战远远超过专业AI。从长远来看,最初的意图是期望最大的模型继续发展,并且在最近引入的游戏环境中它们可以达到甚至超过当前水平。 https://www.chess.com/article/view/chatgpt-gemini-play-cheshttps://www.ches.com/news/news/news/view/ what what--i-model-is-model-is-the-best-the-best-ace-best-achess-chess-chess-kaggy-kaggy-pame-pame-pame-arenahtps一下Google/ai/ai/kaggy-game-arena/https://www.theeregister.com/2025/07/14/atari_chess_vs_vs_gemini/https://www.kaggy.com/benchmarks/kaggy/kaggy/kaggy/chesstextxxt/leadext/leadrerererboard